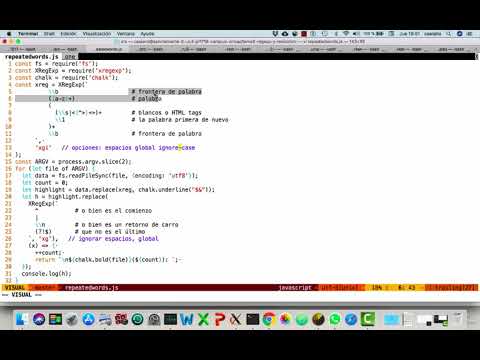
# Introducción a las Expresiones Regulares
# El Constructor
The RegExp constructor creates a regular expression object for matching text with a pattern.
Literal and constructor notations are possible:
/pattern/flags;
new RegExp(pattern [, flags]);
2
- The literal notation provides compilation of the regular expression when the expression is evaluated.
- Use literal notation when the regular expression will remain constant.
- For example, if you use literal notation to construct a regular expression used in a loop, the regular expression won't be recompiled on each iteration.
- The constructor of the regular expression object, for example,
new RegExp("ab+c"), provides runtime compilation of the regular expression. - Use the constructor function when you know the regular expression pattern will be changing, or you don't know the pattern and are getting it from another source, such as user input.
- When using the constructor function, the normal string escape rules
(preceding special characters with
\when included in a string) are necessary. For example, the following are equivalent:
var re = /\w+/;
var re = new RegExp("\\w+");
2
var re = /\w+/;
var re = new RegExp("\\w+");
2
# Ejercicio
- Ejercicio: Usar new Regexp("string") versus slash literal (opens new window). Similitudes y diferencias. Vídeo del profesor
 (opens new window)
(opens new window)- Explique la diferencia observada entre las dos formas de construir una RegExp
# Test
# exec
- RegExp.prototype.exec (opens new window)
The exec() method executes a search for a match in a specified string. Returns a result array, or null.
If you are executing a match simply to find true or false,
use the RegExp.prototype.test() method or the String.prototype.search() method.
# match
- String.prototype.match (opens new window)
- String.prototype.replace (opens new window)
# El operador OR: Circuito Corto
¿Cual es la salida? ¿Porqué?
> "bb".match(/b|bb/)
> "bb".match(/bb|b/)
2
3
# Parenthesis
¿Que casa con cada paréntesis en esta regexp para los pares nombre-valor?
> x = "h = 4"
> r = /([^=]*)(\s*)=(\s*)(.*)/
> r.exec(x)
2
3
Cuando un paréntesis no casa la entrada correspondiente en el array es undefined:
console.log(/bad(ly)?/.exec("bad")); // → ["bad", undefined]
Cuando un paréntesis casa repetidas veces:
console.log(/(\d)+/.exec("123")); // → ["123", "3"]
# Named groups
Remembering groups by their numbers can be hard. An option is to give names to parentheses.
That's done by starting the capture regexp parenthesis by (?<name> and ending with ).
For example, let's look for a date in the format "year-month-day":
let dateRegexp = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
let str = "2019-04-30";
let groups = str.match(dateRegexp).groups;
console.log(groups.year); // 2019
console.log(groups.month); // 04
console.log(groups.day); // 30
2
3
4
5
6
7
8
As you can see, the groups reside in the .groups property of the match.
To look for all dates, we can add flag pattern:g.
> dateRegexp = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/g;
/(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/g
> str = "2019-10-30 2020-01-01";
'2019-10-30 2020-01-01'
2
3
4
We can use matchAll to obtain full matches, together with groups.
The matchAll() method returns an iterator of all results matching a string against a regular expression, including capturing groups.
> results = str.matchAll(dateRegexp)
Object [RegExp String Iterator] {}
> for(let result of results) {
... let {year, month, day} = result.groups;
... console.log(`${day}.${month}.${year}`); }
30.10.2019
01.01.2020
2
3
4
5
6
7
# The Date Class
See EJS: The Date Class (opens new window)
function getDate(string) {
let [_, month, day, year] =
/(\d{1,2})-(\d{1,2})-(\d{4})/.exec(string);
return new Date(year, month - 1, day);
}
console.log(getDate("1-30-2003"));
// → Thu Jan 30 2003 00:00:00 GMT+0100 (CET)
2
3
4
5
6
7
# Word and string boundaries
See EJS: Word and string boundaries (opens new window)
> /\d+/.exec('b45a')
[ '45', index: 1, input: 'b45a' ]
> /^\d+$/.exec('b45a')
null
2
3
4
console.log(/cat/.test("concatenate"));
// → true
console.log(/\bcat\b/.test("concatenate"));
// → false
2
3
4
# Backreferences in pattern: \N and \k<name>
We can use the contents of capturing groups (...) not only in the result or in the replacement string, but also in the pattern itself.
# By Number
A backreference \#n inside a regexp, where #n is a positive integer. A back reference to the last substring matching the #n parenthesis in the regular expression (counting from the left).
For example, /apple(,)\sorange\1/ matches 'apple, orange,' in "apple, orange, cherry, peach."
See also section Backreferences in pattern: \N and \k<name> (opens new window) of the book The Modern JavaScript Tutorial
> chuchu = /^(a+)-\1$/
/^(a+)-\1$/
> chuchu.exec("aa-aa")
[ 'aa-aa', 'aa', index: 0, input: 'aa-aa' ]
> chuchu.exec("aa-a")
null
> chuchu.exec("a-a")
[ 'a-a', 'a', index: 0, input: 'a-a' ]
> chuchu.exec("a-ab")
null
2
3
4
5
6
7
8
9
10
# Forward References
In Ruby and Perl forward references can also be used, but be sure the referenced parenthesis
has matched when is going to be used. This usually means that the forward reference
is inside some repetition group. For example, in Ruby this regexp matches with train only if
it is prefixed by at least one choo:
$ irb
irb(main):052:0> regex = /(\2train|(choo))+/
=> /(\2train|(choo))+/
irb(main):053:0> 'choochootrain' =~ regex
=> 0
irb(main):054:0> $&
=> "choochootrain"
irb(main):055:0> $1
=> "chootrain"
irb(main):056:0> $2
=> "choo"
irb(main):004:0> 'train' =~ regex
=> nil
2
3
4
5
6
7
8
9
10
11
12
13
This is not the case in JavaScript:
[~/.../github-actions/225-github-actions-demo(master)]$ node
Welcome to Node.js v13.5.0.
Type ".help" for more information.
> regex = /(\2train|(choo))+/
/(\2train|(choo))+/
> regex.exec('train')
[
'train',
'train',
undefined,
index: 0,
input: 'train',
groups: undefined
]
2
3
4
5
6
7
8
9
10
11
12
13
14
In fact, it does match train (The \2 is assumed empty):
# By Name
To reference a named group we can use \k<name>
[~/javascript-learning/xregexpexample(gh-pages)]$ nvm use v13
Now using node v13.5.0 (npm v6.13.4)
> regexp = /(?<quote>['"])([^'"]*)\k<quote>/;
/(?<quote>['"])([^'"]*)\k<quote>/
> `He said: "She is the one!".`.match(regexp)
[
'"She is the one!"',
'"',
'She is the one!',
index: 9,
input: 'He said: "She is the one!".',
groups: [Object: null prototype] { quote: '"' }
]
2
3
4
5
6
7
8
9
10
11
12
13
Be sure to use a modern version of JS:
[~/javascript-learning/xregexpexample(gh-pages)]$ node --version
v8.1.2
> regexp = /(?<quote>['"])([^'"]*)\k<quote>/;
SyntaxError: Invalid regular expression: /(?<quote>['"])(.*?)\k<quote>/: Invalid group
2
3
4
# Backtracking en Expresiones Regulares
¿Con que cadenas casa la expresión regular /^(11+)\1+$/?
> '1111'.match(/^(11+)\1+$/) # 4 unos
[ '1111',
'11',
index: 0,
input: '1111' ]
> '111'.match(/^(11+)\1+$/) # 3 unos
null
> '11111'.match(/^(11+)\1+$/) # 5 unos
null
> '111111'.match(/^(11+)\1+$/) # 6 unos
[ '111111',
'111',
index: 0,
input: '111111' ]
> '11111111'.match(/^(11+)\1+$/) # 8 unos
[ '11111111',
'1111',
index: 0,
input: '11111111' ]
> '1111111'.match(/^(11+)\1+$/)
null
>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Diophantic Equations
A Diophantine equation is an indeterminate polynomial equation that allows the variables to be integers only.
On September 2009 I (opens new window) wrote a small piece in Perl Monks (opens new window) titled:
that illustrates (in Perl) how to solve a set of diophantine equations using Perl Extended Regular Expressions.
# Exercise: Write a function that solves Diophantine Equations
Write a program that using a regular expression computes a integer solution to the diophantine equation
Generalize the former solution and write a function:
diophantine(a, b, c)
that returns an array [x, y] containing a
solution to the diophantine equation
null if there is no such solution Since to solve this problem you have to dynamically create the regexp, review section Dynamically creating RegExp objects (opens new window) of the Eloquent JS book.
# replace
The replace() method of the String objects returns a new string with some or all matches of
a pattern replaced by a replacement.
The pattern can be a string or a RegExp,
and the replacement can be a string or a function to be called
for each match.
> re = /apples/gi
/apples/gi
> str = "Apples are round, and apples are juicy."
'Apples are round, and apples are juicy.'
> newstr = str.replace(re, "oranges")
'oranges are round, and oranges are juicy.'
2
3
4
5
6
We can refer to matched groups in the replacement string:
console.log(
"Liskov, Barbara\nMcCarthy, John\nWadler, Philip"
.replace(/(\w+), (\w+)/g, "$2 $1"));
// → Barbara Liskov
// John McCarthy
// Philip Wadler
2
3
4
5
6
The $1 and $2 in the replacement string refer to the parenthesized groups in the pattern.
# Using a function to compute the replacement string
The replacement string can be a function to be invoked to create the new substring (to put in place of the substring received):
let s = "the cia and fbi";
console.log(s.replace(/\b(fbi|cia)\b/g,
str => str.toUpperCase()));
// → the CIA and FBI
2
3
4
The arguments supplied to this function
(match, p1, p2, ..., pn, offset, string) => { ... }
are:
| Possible name | Supplied value |
|---|---|
| match | The matched substring. (Corresponds to $&.) |
p1, p2, ... | The nth parenthesized submatch string, provided the first argument to replace was a RegExp object. (Corresponds to $1, $2, etc.) For example, if /(\a+)(\b+)/, was given, p1 is the match for \a+, and p2 for \b+. |
offset | The offset of the matched substring within the total string being examined (For example, if the total string was "abcd", and the matched substring was "bc", then this argument will be 1 |
| string | The total string being examined |
# Ejemplo: Fahrenheit a Celsius
El siguiente ejemplo reemplaza los grados Fahrenheit con su equivalente en grados Celsius.
Los grados Fahrenheit deberían ser un número acabado en F.
La función devuelve el número Celsius acabado en C.
Por ejemplo, si el número de entrada es 212F, la función devuelve 100C. Si el número es 0F, la función devuelve -17.77777777777778C.
Véase solución en codepen (opens new window).
[~/javascript/learning]$ pwd -P
/Users/casiano/local/src/javascript/learning
[~/javascript/learning]$ cat f2c.js
2
3
#!/usr/bin/env node
function f2c(x)
{
function convert(str, p1, offset, s)
{
return ((parseFloat(p1)-32) * 5/9) + "C";
}
var s = String(x);
var test = /(\d+(?:\.\d*)?)F\b/g;
return s.replace(test, convert);
}
var arg = process.argv[2] || "32F";
console.log(f2c(arg));
2
3
4
5
6
7
8
9
10
11
12
13
14
Ejecución:
[~/javascript/learning]$ ./f2c.js 100F
37.77777777777778C
[~/javascript/learning]$ ./f2c.js
0C
2
3
4
# Greed and Lazy Operators
# Exercise: Replace all double quotes with single quotes:
We have a text and need to replace all double quotes "..." with single quotes: '...'. (We are not considering escaped double quotes inside)
What is the output for this regexp?:
let regexp = /".+"/g;
let str = 'a "witch" and her "broom" is one';
str.match(regexp);
2
3
See Greedy and lazy quantifiers (opens new window) at the Modern JavaScript book
# Exercise: Write a function that removes all comments
Write a function that removes all comments from a piece of JavaScript code.
What is the output?
function stripComments(code) {
return code.replace(/\/\*[^]*\*\//g, "");
}
console.log(stripComments("1 + /* 2 */3"));
console.log(stripComments("1 /* a */+/* b */ 1"));
2
3
4
5
# Lazy Quantifiers
The lazy mode of quantifiers is an opposite to the greedy mode. It means: repeat minimal number of times.
We can enable it by putting a question mark ? after the quantifier, so that it becomes *? or +? or even ?? for ?.
When a question mark ? is added after another quantifier it switches the matching mode from greedy to lazy.
# Positive Lookahead
A positive lookahead has the syntax X(?=Y):
The regular expression engine finds X
and then matches only if there’s Y immediately after it and the search continues
inmediately after the X.
For more information, see section Lookahead and lookbehind (opens new window) of the Modern JavaScript Tutorial.
Example:
> x = "hello"
'hello'
> r = /l(?=o)/
/l(?=o)/
> z = r.exec(x)
[ 'l', index: 3, input: 'hello' ]
2
3
4
5
6
Exercise: What is the output?
> str = "1 turkey costs 30 €"
'1 turkey costs 30 €'
> str.match(/\d+(?=\s)(?=.*30)/)
2
3
# Negative Lookahead
A negative lookahead has the syntax X(!=Y):
The regular expression engine finds X
and then matches only if there’s no Y immediately after the X and if so,
the search continues
inmediately after the X.
Exercise: What is the output? Whose of these twos is matched?
> reg = /\d+(?!€)(?!\$)/
/\d+(?!€)(?!\$)/
> s = '2€ is more than 2$ and 2+2 is 4'
'2€ is more than 2$ and 2+2 is 4'
> reg.exec(s)
2
3
4
5
# Positive Lookbehind
Positive lookbehind has the syntax (?<=Y)X,
it matches X, but only if there’s Y before it.
> str = "1 turkey costs $30"
'1 turkey costs $30'
> str.match(/(?<=\$)\d+/)
[ '30', index: 16, input: '1 turkey costs $30', groups: undefined ]
2
3
4
# Negative Lookbehind
Negative lookbehind has the syntax (?<!Y)X, it matches X,
but only if there’s no Y before it.
> str = 'I bought 2Kg of rice by 3€ at the Orotavas\' country market'
"I bought 2Kg of rice by 3€ at the Orotavas' country market"
> str.match(/(?<!t )\d+/)
[
'3',
index: 24,
input: "I bought 2Kg of rice by 3€ at the Orotavas' country market",
groups: undefined
]
2
3
4
5
6
7
8
9
# Ejercicio: Poner Blanco después de Coma
Busque una solución al siguiente ejercicio (véase ’Regex to add space after punctuation sign’ en PerlMonks (opens new window)). Se quiere poner un espacio en blanco después de la aparición de cada coma:
> x = "a,b,c,1,2,d, e,f"
'a,b,c,1,2,d, e,f'
> x.replace(/,/g,", ")
'a, b, c, 1, 2, d, e, f'
2
3
4
pero se quiere que
- la sustitución no tenga lugar si la coma esta incrustada entre dos dígitos.
- Además se pide que si hay ya un espacio después de la coma, no se duplique.
La siguiente solución logra el segundo objetivo, pero estropea los números:
> x = "a,b,c,1,2,d, e,f"
'a,b,c,1,2,d, e,f'
> x.replace(/,(\S)/g,", $1")
'a, b, c, 1, 2, d, e, f'
2
3
4
Esta otra funciona bien con los números pero no con los espacios ya existentes:
> x = "a,b,c,1,2,d, e,f"
'a,b,c,1,2,d, e,f'
> x.replace(/,(\D)/g,", $1")
'a, b, c,1,2, d, e, f'
2
3
4
Explique cuando casa esta expresión regular:
> r = /(\d[,.]\d)|(,(?=\S))/g
/(\d[,.]\d)|(,(?=\S))/g
2
Aproveche que el método replace puede recibir como segundo argumento una función (vea
replace (opens new window)):
> z = "a,b,1,2,d, 3,4,e"
'a,b,1,2,d, 3,4,e'
> r = /(\d[,.]\d)|(,(?=\S))/g
/(\d[,.]\d)|(,(?=\S))/g
> f = (_, p1, p2) => (p1 || p2 + " ")
[Function]
> z.replace(r, f)
'a, b, 1,2, d, 3,4, e'
2
3
4
5
6
7
8
Véase en codepen (opens new window)
# search
- String.prototype.search (opens new window)
str.search(regexp)
If successful, search returns the index of the regular expression inside
the string. Otherwise, it returns -1.
When you want to know whether a pattern is found in a string use search
(similar to the regular expression test method); for more information
(but slower execution) use match (similar to the regular expression
exec method).
" word".search(/\S/)
// → 2
" ".search(/\S/)
// → -1
2
3
4
There is no way to indicate that the match should start at a given offset (like we can with the second argument to indexOf (opens new window)). However, you can do something as convolute like this!:
> z = " word"
' word'
> z.search(/(?<=^.{4})\S/ // search will match after offset 5
4
> z[4]
'r'
2
3
4
5
6
# Parsing Ficheros ini
- Parsing an INI file (opens new window) Eloquent JavaScript
# Otra Solución al Parsing de los Ficheros ini
A web app with a lexical analyzer of INI files:
- Parsing ini files (opens new window): deployment
- Repo con el código del parsing de ficheros ini (opens new window)
- ini.js (opens new window) entry file
# Ejercicios
- Ejercicios de Expresiones Regulares en los apuntes
- Ejercicio: Palabras repetidas (opens new window) Vídeo del profesor
- Ejercicio: Buscar las secuencias que empiezan por 12 en posiciones múltiplos de 6 (opens new window) Vídeo del profesor
- Tarea. Haga los ejercicios en https://regexone.com/ (opens new window)
- Tarea. Haga los ejercicios en https://www.w3resource.com/javascript-exercises/javascript-regexp-exercises.php (opens new window)