
# Unicode, UTF-16 and JavaScript
# The Unicode Standard
The way JavaScript models Strings is based on the Unicode standard.
This standard assigns a number called code point to virtually every character you would ever need, including characters from Greek, Arabic, Japanese, Armenian, and so on. If we have a number for every character, a string can be described by a sequence of numbers.
One advantage of Unicode over other possible sets is that
- The first 256 code points are identical to ISO-8859-1 (opens new window), and hence also ASCII.
- In addition, the vast majority of commonly used characters are representable by only two bytes, in a region called the Basic Multilingual Plane (BMP) (opens new window).
# Planes
In the Unicode (opens new window) standard, a plane is a continuous group of 65,536 (
The BMP is the first (code points from U+0000 to U+FFFF), the other 16 planes are called astral planes. Worth noting that planes 3 to 13 are currently empty.
The code points contained in astral planes are called astral code points.
Astral code points go from U+10000 to U+10FFFF.
JavaScript’s representation uses 16 bits per string element, which can describe up to
When comparing strings, JavaScript goes over the characters from left to right, comparing the Unicode codes one by one.
# Private Use Areas (PUA)
In Unicode (opens new window), a Private Use Area (PUA) is a range of code points (opens new window) that, by definition, will not be assigned characters by the Unicode Consortium (opens new window).
Three private use areas are defined: one in the Basic Multilingual Plane (opens new window) (U+E000–U+F8FF), and one each in, and nearly covering, planes 15 and 16 (opens new window) (U+F0000–U+FFFFD, U+100000–U+10FFFD).
The code points in these areas cannot be considered as standardized characters in Unicode itself. They are intentionally left undefined so that third parties may define their own characters without conflicting with Unicode Consortium assignments. The Private Use Areas will remain allocated for that purpose in all future Unicode versions.
# UTF-16
JavaScript strings are encoded as a sequence of 16-bit numbers. These are called code units.
A Unicode character code was initially supposed to fit within such a unit (which gives you a little over 65,000 characters). When it became clear that wasn’t going to be enough, many people balked at the need to use more memory per character.
To address these concerns, UTF-16 (UCS Transformation Format for 16 Planes of Group 00), the format used by JavaScript strings, was invented. It describes most common characters using a single 16-bit code unit but uses a pair of two such units for others.
# JS and UTF-16 and Problems Processing Strings
Some people think UTF-16 is a bad idea: It’s easy to write programs that pretend code units and characters are the same thing.
If your language doesn’t use two-unit characters, that will appear to work just fine. But as soon as someone tries to use such a program with some less common characters, it breaks. Fortunately, with the advent of emoji, everybody has started using two-unit characters, and the burden of dealing with such problems is more fairly distributed.
Unfortunately, obvious operations on JavaScript strings, such as getting their length through the length property and accessing their content using square brackets, deal only with code units.
// Two emoji characters, horse and shoe
let horseShoe = "🐴👟";
console.log("horseShoe.length ="+horseShoe.length);
// → 4 four code units but two code points
2
3
4
You can use the spread operator (...) to turn strings into arrays
and compute the length of the string and access the character at
a given position:
console.log("[...'abc'] = "+inspect([...'abc'])); // [ 'a', 'b', 'c' ]
console.log("[...'🐴👟'].length = "+[...'🐴👟'].length);
// → 2
console.log(horseShoe[0]);
// → (Invalid half-character)
console.log([...horseShoe][0]);
// 🐴
2
3
4
5
6
7
See this code (opens new window) at repo ULL-ESIT-PL/unicode-js.
Another example is reversing a string. Let us define the reversefunction like this:
> reverse = str => str.split('').reverse().join('')
[Function: reverse]
2
It seems to work:
> reverse('mañana')
'anañam'
2
However, it messes up strings that contain combining marks or astral symbols:
> reverse('💩🍎')
'�🂩�'
2
To reverse astral symbols correctly we can use again the spread operator:
> reverse = str => [...str].reverse().join('')
[Function: reverse]
> reverse('💩🍎')
'🍎💩'
2
3
4
JavaScript’s charCodeAt method gives you a code unit, not a full character code. The codePointAt method, added later, does give a full Unicode character.
So we could use that to get characters from a string.
But the argument passed to codePointAt is still an index into the sequence of code units.
So to run over all characters in a string, we’d still need to deal with the question of whether a character takes up one or two code units.
A for/of loop can be used to iterate on strings.
for (let ch of "🐴👟") {
console.log(ch + " has " + ch.length + " units"); // 2 units
}
2
3
Like codePointAt, this type of loop was introduced at a time where people were acutely aware of the problems with UTF-16. When you use it to loop over a string, it gives you real characters, not code units.
[~/.../clases/20200325-miercoles(master)]$ cat stringTraversing.js
const len = (x) => [...x].length;
String.prototype.char = function(i) { return [...this][i]; }
let str = "🌹🐉";
for (let i=0; i<len(str); i++) {
console.log(
`${str.codePointAt(i)} (${str.charCodeAt(2*i)}, ${str.charCodeAt(2*i+1)}) => ${str.char(i)}`
);
}
2
3
4
5
6
7
8
9
Execution:
[~/.../clases/20200325-miercoles(master)]$ node stringTraversing.js
127801 (55356, 57145) => 🌹
57145 (55357, 56329) => 🐉
2
3
If you have a character (which will be a string of one or two code units), you can use codePointAt() to get its code point and charCodeAt to get its code unit.
let horseShoe = "🐴👟";
console.log("ABC".charCodeAt(0)); // returns 65
console.log("ABC".charCodeAt(1)); // returns 66
console.log(horseShoe.charCodeAt(0));
// → 55357 (Code of the half-character)
console.log(horseShoe.charCodeAt(1));
// → 56372
console.log(horseShoe.charCodeAt(2));
// → 55357
console.log(horseShoe.charCodeAt(3));
// → 56415
console.log(horseShoe.codePointAt(0));
// → 128052 (Actual code for horse emoji)
console.log(horseShoe.codePointAt(2));
// → 128095 (Actual code for shoe emoji)
console.log(String.fromCharCode(55357, 56372, 55357, 56415)); // → 🐴👟
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- Examples of JavaScript y Unicode (opens new window) (Repo en GitHub unicode-js)
# Checking if a Codepoint is in the Basic Multilingual Plane BMP
A natural question seems to be:
How to know if a codepoint is inside the BMP or is astral?
Did you realize in the former examples that all the first code units of all emojis were quite large?. They were larger than 55295?
The following code seems to work. The last BMP Character seems to be 0xD7FF (55295) (opens new window):
[~/.../clases/20200325-miercoles(master)]$ cat is-bmp.js
const isInRange = (str) => /[\u0000-\ud7ff]/u.test(str);
const isISO8859 = char => char.charCodeAt(0) < 255;
const isBMP = char => char.charCodeAt(0) <= 0xD7FF;
const checkIf = (condition, char) => {
console.log(
`${char} with codePoint ${char.codePointAt(0)}`
+ ` and charCodeAt(0) ${char.charCodeAt(0)}`
+ ` ${condition.name}(${char})=${condition(char)}`
+ ` isInRange=${isInRange(char)}`);
};
console.log("-----ISO8859-----")
checkIf(isISO8859,"A"); // true
checkIf(isISO8859,"ñ"); // true
checkIf(isISO8859,"α"); // false
checkIf(isISO8859,"п"); // false
checkIf(isISO8859,"👟"); // false
console.log("-----BMP-----")
checkIf(isBMP,"A"); // true
checkIf(isBMP,"ñ"); // true
checkIf(isBMP,"α"); // true
checkIf(isBMP,"п"); // true
checkIf(isBMP,"𨭎"); // false
checkIf(isBMP,"👟"); // false
checkIf(isBMP,"🐴"); // false
checkIf(isBMP,"😂"); // false
checkIf(isBMP,'﷽ '); // The longest single character I ever seen!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Execution:
[~/.../clases/20200325-miercoles(master)]$ node is-bmp.js
-----ISO8859-----
A with codePoint 65 and charCodeAt(0) 65 isISO8859(A)=true isInRange=true
ñ with codePoint 241 and charCodeAt(0) 241 isISO8859(ñ)=true isInRange=true
α with codePoint 945 and charCodeAt(0) 945 isISO8859(α)=false isInRange=true
п with codePoint 1087 and charCodeAt(0) 1087 isISO8859(п)=false isInRange=true
👟 with codePoint 128095 and charCodeAt(0) 55357 isISO8859(👟)=false isInRange=false
-----BMP-----
A with codePoint 65 and charCodeAt(0) 65 isBMP(A)=true isInRange=true
ñ with codePoint 241 and charCodeAt(0) 241 isBMP(ñ)=true isInRange=true
α with codePoint 945 and charCodeAt(0) 945 isBMP(α)=true isInRange=true
п with codePoint 1087 and charCodeAt(0) 1087 isBMP(п)=true isInRange=true
𨭎 with codePoint 166734 and charCodeAt(0) 55394 isBMP(𨭎)=false isInRange=false
👟 with codePoint 128095 and charCodeAt(0) 55357 isBMP(👟)=false isInRange=false
🐴 with codePoint 128052 and charCodeAt(0) 55357 isBMP(🐴)=false isInRange=false
😂 with codePoint 128514 and charCodeAt(0) 55357 isBMP(😂)=false isInRange=false
﷽ with codePoint 65021 and charCodeAt(0) 65021 isBMP(﷽ )=false isInRange=true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
See BMP (opens new window) en la Wikipedia.
See also this page in Unicode.org (opens new window) to see the properties of a given unicode character. Among the if the codepoint belongs to the BMP.
# Unicode and Editors
- Visual Studio Code Extension: Insert Unicode (opens new window)
- En Vim:
gashows the decimal, hexadecimal and octal value of the character under the cursor.- Any utf character at all can be entered with a
Ctrl-Vprefix, either<Ctrl-V> u aaaaor<Ctrl-V> U bbbbbbbb, with0 <= aaaa <= FFFF, or0 <= bbbbbbbb <= 7FFFFFFF. - Digraphs work by pressing CTRL-K and a two-letter combination while in insert mode.
<Ctrl-K> a *producesα<Ctrl-K> b *producesβ,<Ctrl-k> d =producesд, etc.
# Unicode: Regular Expressions and International characters
EloquentJS: International characters (opens new window)
Because of JavaScript’s initial simplistic implementation and the fact that this simplistic approach was later set in stone as standard behavior, JavaScript’s regular expressions are rather dumb about characters that do not appear in the English language.
For example, as far as JavaScript’s regular expressions are concerned, a word character is only one of the 26 characters in the Latin alphabet (uppercase or lowercase), decimal digits, and, for some reason, the underscore character. Things like é or β, which most definitely are word characters, will not match \w (and will match uppercase \W, the nonword category).
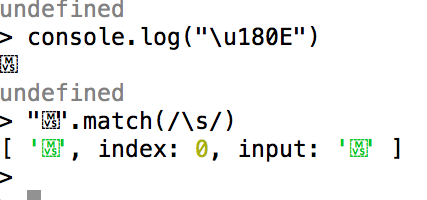
# \s: Strange behaviors
By a strange historical accident, \s (whitespace) does not have this problem and matches all characters that the Unicode standard
considers whitespace, including things like the nonbreaking space
and the Mongolian vowel separator:
# Option /u
By default, regular expressions work on code units:
See this example in this repo ULL-ESIT-PL/unicode-js (opens new window)
[~/.../src/unicode-js(master)]$ cat apple-regexp-test.js
console.log(/🍎{3}/.test("🍎🍎🍎"));
// → false
console.log(/🍎{3}/u.test("🍎🍎🍎"));
// → true
console.log(/<.>/.test("<🌹>"));
// → false
console.log(/<.>/u.test("<🌹>"));
// → true
2
3
4
5
6
7
8
9
The problem is that the code point 🍎 in the first line
is treated as two code units,
and the /🍎{3}/ part is interpreted as 3 repetitions of the second code unit.
Similarly, the dot matches a single code unit, not the two that make up the rose emoji.
You must add a u option (for Unicode) to your regular expression to make it treat such characters properly. The wrong behavior remains the default, unfortunately, because changing that might cause problems for existing code that depends on it.
# The notation "\u#codepoint" inside a string
\u inside a string allow us to introduce unicode characters using
\u#codepoint:
> console.log("\u03A0")
Π
> console.log("\u03B1")
α
> "Πα".match(/\u03A0(\u03B1)/u)
[ 'Πα', 'α', index: 0, input: 'Πα' ]
2
3
4
5
6
# \p macro: properties
Every character in Unicode has a lot of properties. They describe what category the character belongs to, contain miscellaneous information about it.
For instance, if a character has Letter property, it means that the character belongs to an alphabet (of any language).
And Number property means that it’s a digit: maybe Arabic or Chinese, and so on.
The \p macro can be used in any regular expression using the /u option to match the characters to which the Unicode standard assigns the specified Unicode property (opens new window).
For instance, \p{Letter} denotes a letter in any of language. We can also use \p{L}, as L is an alias of Letter.
There are shorter aliases for almost every property.
ost of the Unicode characters are associated with a specific script. The standard contains 140 different scripts — 81 are still in use today, and 59 are historic.
People are writing texts in at least 80 other writing systems, many of which We wouldn’t even recognize. For example, here’s a sample of Tamil handwriting:

For example:
[~/.../src/unicode-js(master)]$ cat property.js
console.log(/\p{Script=Greek}/u.test("α"));
// → true
console.log(/\p{Script=Arabic}/u.test("α"));
// → false
console.log(/\p{Alphabetic}/u.test("α"));
// → true
console.log(/\p{Alphabetic}/u.test("!"));
// → false
console.log(/\p{Number}/u.test("६६७"));
// → true
2
3
4
5
6
7
8
9
10
Here is a regexp that matches identifiers:
> "\u216B"
'Ⅻ'
> id = /[\p{L}_][\p{L}\p{N}_]*/ug
/[\p{L}_][\p{L}\p{N}_]*/gu
> 'Русский६ 45 ; ab2 ... αβ६६७ -- __ b\u216B'.match(id)
[ 'Русский६', 'ab2', 'αβ६६७', '__', 'bⅫ' ]
2
3
4
5
6
Unicode supports many different properties, their full list would require more space than we have here. For more, see this references:
- Properties by a character: https://unicode.org/cldr/utility/character.jsp (opens new window).
- Characters by a property: https://unicode.org/cldr/utility/list-unicodeset.jsp (opens new window).
- Short aliases for properties: https://www.unicode.org/Public/UCD/latest/ucd/PropertyValueAliases.txt (opens new window).
- A full base of Unicode characters in text format, with all properties: https://www.unicode.org/Public/UCD/latest/ucd/ (opens new window).
# Read Also
- Unicode.org (opens new window)
- See section Unicode properties \p{...} (opens new window) of the Modern Javascript book for a list of properties and more examples about
\p - JavaScript has a Unicode problem (opens new window) 2013
- Eloquent JS: International characters (opens new window)
# XRegExp: Expresiones Regulares Extendidas (a la Perl)
GitHub repo ilustrando el uso de XRegExp URL (opens new window)
Original slevithan/xregexp repo en GitHub. Documentación (opens new window)
https://xregexp.com/ website (opens new window): Documentación
# API de XRegExp (opens new window)
- XRegExp (opens new window)
- XRegExp.addToken (opens new window)
- XRegExp.build (opens new window) (addon)
- XRegExp.cache (opens new window)
- XRegExp.escape (opens new window)
- XRegExp.exec (opens new window)
- XRegExp.forEach (opens new window)
- XRegExp.globalize (opens new window)
- XRegExp.install (opens new window)
- XRegExp.isInstalled (opens new window)
- XRegExp.isRegExp (opens new window)
- XRegExp.match (opens new window)
- XRegExp.matchChain (opens new window)
- XRegExp.matchRecursive (opens new window) (addon)
- XRegExp.replace (opens new window)
- XRegExp.replaceEach (opens new window)
- XRegExp.split (opens new window)
- XRegExp.test (opens new window)
- XRegExp.uninstall (opens new window)
- XRegExp.union (opens new window)
- XRegExp.version (opens new window)
# XRegExp instance properties
- <regexp>.xregexp.source (opens new window) (The original pattern provided to the XRegExp constructor)
- <regexp>.xregexp.flags (opens new window) (The original flags provided to the XRegExp constructor)
# XRegExp. Unicode
- XRegExp Plugins (opens new window)
- Regular Expressions.info: Unicode Regular Expressions (opens new window)
# Módulo @ull-esit-pl/uninums
Javascript supports Unicode strings, but parsing such strings to numbers is unsupported (e.g., the user enters a phone number using Chinese numerals).
uninums.js (opens new window) is a small utility script that implements five methods for handling non-ASCII numerals in Javascript
- Módulo @ull-esit-pl/uninums (opens new window)
> uninums = require("@ull-esit-pl/uninums")
{ normalSpaces: [Function: normalSpaces],
normalDigits: [Function: normalDigits],
parseUniInt: [Function: parseUniInt],
parseUniFloat: [Function: parseUniFloat],
sortNumeric: [Function: sortNumeric] }
> uninums.parseUniInt('६.६')
6
> uninums.parseUniFloat('६.६')
6.6
> uninums.parseUniFloat('६.६e६')
6600000
> uninums.sortNumeric(['٣ dogs','١٠ cats','٢ mice'])
[ '٢ mice', '٣ dogs', '١٠ cats' ]
> uninums.normalDigits('٢ mice')
'2 mice'
> uninums.normalDigits('٣ dog')
'3 dog'
> uninums.normalDigits('١٠ cats')
'10 cats'
> uninums.normalDigits('٠۴६')
'046'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
> uninums = require("@ull-esit-pl/uninums")
{ normalSpaces: [Function: normalSpaces],
normalDigits: [Function: normalDigits],
parseUniInt: [Function: parseUniInt],
parseUniFloat: [Function: parseUniFloat],
sortNumeric: [Function: sortNumeric] }
> uninums.parseUniInt('६.६')
6
> uninums.parseUniFloat('६.६')
6.6
> uninums.parseUniFloat('६.६e६')
6600000
> uninums.sortNumeric(['٣ dogs','١٠ cats','٢ mice'])
[ '٢ mice', '٣ dogs', '١٠ cats' ]
> uninums.normalDigits('٢ mice')
'2 mice'
> uninums.normalDigits('٣ dog')
'3 dog'
> uninums.normalDigits('١٠ cats')
'10 cats'
> uninums.normalDigits('٠۴६')
'046'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22